
In fashionable knowledge architectures, Apache Iceberg has emerged as a preferred desk format for knowledge lakes, providing key options together with ACID transactions and concurrent write help. Though these capabilities are highly effective, implementing them successfully in manufacturing environments presents distinctive challenges that require cautious consideration.
Contemplate a typical state of affairs: A streaming pipeline repeatedly writes knowledge to an Iceberg desk whereas scheduled upkeep jobs carry out compaction operations. Though Iceberg gives built-in mechanisms to deal with concurrent writes, sure battle situations—reminiscent of between streaming updates and compaction operations—can result in transaction failures that require particular dealing with patterns.
This publish demonstrates learn how to implement dependable concurrent write dealing with mechanisms in Iceberg tables. We are going to discover Iceberg’s concurrency mannequin, study frequent battle situations, and supply sensible implementation patterns of each computerized retry mechanisms and conditions requiring customized battle decision logic for constructing resilient knowledge pipelines. We may even cowl the sample with computerized compaction via AWS Glue Information Catalog desk optimization.
Frequent battle situations
Essentially the most frequent knowledge conflicts happen in a number of particular operational situations that many organizations encounter of their knowledge pipelines, which we focus on on this part.
Concurrent UPDATE/DELETE on overlapping partitions
When a number of processes try to change the identical partition concurrently, knowledge conflicts can come up. For instance, think about a knowledge high quality course of updating buyer information with corrected addresses whereas one other course of is deleting outdated buyer information. Each operations goal the identical partition primarily based on customer_id, resulting in potential conflicts as a result of they’re modifying an overlapping dataset. These conflicts are notably frequent in large-scale knowledge cleanup operations.
Compaction vs. streaming writes
A basic battle state of affairs happens throughout desk upkeep operations. Contemplate a streaming pipeline ingesting real-time occasion knowledge whereas a scheduled compaction job runs to optimize file sizes. The streaming course of is perhaps writing new information to a partition whereas the compaction job is making an attempt to mix current recordsdata in the identical partition. This state of affairs is very frequent with Information Catalog desk optimization, the place computerized compaction can run concurrently with steady knowledge ingestion.
Concurrent MERGE operations
MERGE operations are notably prone to conflicts as a result of they contain each studying and writing knowledge. For example, an hourly job is perhaps merging buyer profile updates from a supply system whereas a separate job is merging desire updates from one other system. If each jobs try to change the identical buyer information, they will battle as a result of every operation bases its modifications on a special view of the present knowledge state.
Normal concurrent desk updates
When a number of transactions happen concurrently, some transactions would possibly fail to decide to the catalog as a result of interference from different transactions. Iceberg has mechanisms to deal with this state of affairs, so it could possibly adapt to concurrent transactions in lots of instances. Nonetheless, commits can nonetheless fail if the most recent metadata is up to date after the bottom metadata model is established. This state of affairs applies to any kind of updates on an Iceberg desk.
Iceberg’s concurrency mannequin and battle kind
Earlier than diving into particular implementation patterns, it’s important to grasp how Iceberg manages concurrent writes via its desk structure and transaction mannequin. Iceberg makes use of a layered structure to handle desk state and knowledge:
- Catalog layer – Maintains a pointer to the present desk metadata file, serving as the only supply of fact for desk state. The Information Catalog gives the performance because the Iceberg catalog.
- Metadata layer – Incorporates metadata recordsdata that observe desk historical past, schema evolution, and snapshot data. These recordsdata are saved on Amazon Easy Storage Service (Amazon S3).
- Information layer – Shops the precise knowledge recordsdata and delete recordsdata (for Merge-on-Learn operations). These recordsdata are additionally saved on Amazon S3.
The next diagram illustrates this structure.

This structure is prime to Iceberg’s optimistic concurrency management, the place a number of writers can proceed with their operations concurrently, and conflicts are detected at commit time.
Write transaction move
A typical write transaction in Iceberg follows these key steps:
- Learn present state. In lots of operations (like OVERWRITE, MERGE, and DELETE), the question engine must know which recordsdata or rows are related, so it reads the present desk snapshot. That is non-compulsory for operations like INSERT.
- Decide the modifications in transaction, and write new knowledge recordsdata.
- Load the desk’s newest metadata, and decide which metadata model is used as the bottom for the replace.
- Verify if the change ready in Step 2 is suitable with the most recent desk knowledge in Step 3. If the examine failed, the transaction should cease.
- Generate new metadata recordsdata.
- Commit the metadata recordsdata to the catalog. If the commit failed, retry from Step 3. The variety of retries is determined by the configuration.
The next diagram illustrates this workflow.

Conflicts can happen at two vital factors:
- Information replace conflicts – Throughout validation when checking for knowledge conflicts (Step 4)
- Catalog commit conflicts – In the course of the commit when making an attempt to replace the catalog pointer (Step 6)
When working with Iceberg tables, understanding the sorts of conflicts that may happen and the way they’re dealt with is essential for constructing dependable knowledge pipelines. Let’s study the 2 main sorts of conflicts and their traits.
Catalog commit conflicts
Catalog commit conflicts happen when a number of writers try and replace the desk metadata concurrently. When a commit battle happens, Iceberg will routinely retry the operation primarily based on the desk’s write properties. The retry course of solely repeats the metadata commit, not the complete transaction, making it each protected and environment friendly. When the retries fail, the transaction fails with CommitFailedException.
Within the following diagram, two transactions run concurrently. Transaction 1 efficiently updates the desk’s newest snapshot within the Iceberg catalog from 0 to 1. In the meantime, transaction 2 makes an attempt to replace from Snapshot 0 to 1, however when it tries to commit the modifications to the catalog, it finds that the most recent snapshot has already been modified to 1 by transaction 1. Consequently, transaction 2 must retry from Step 3.
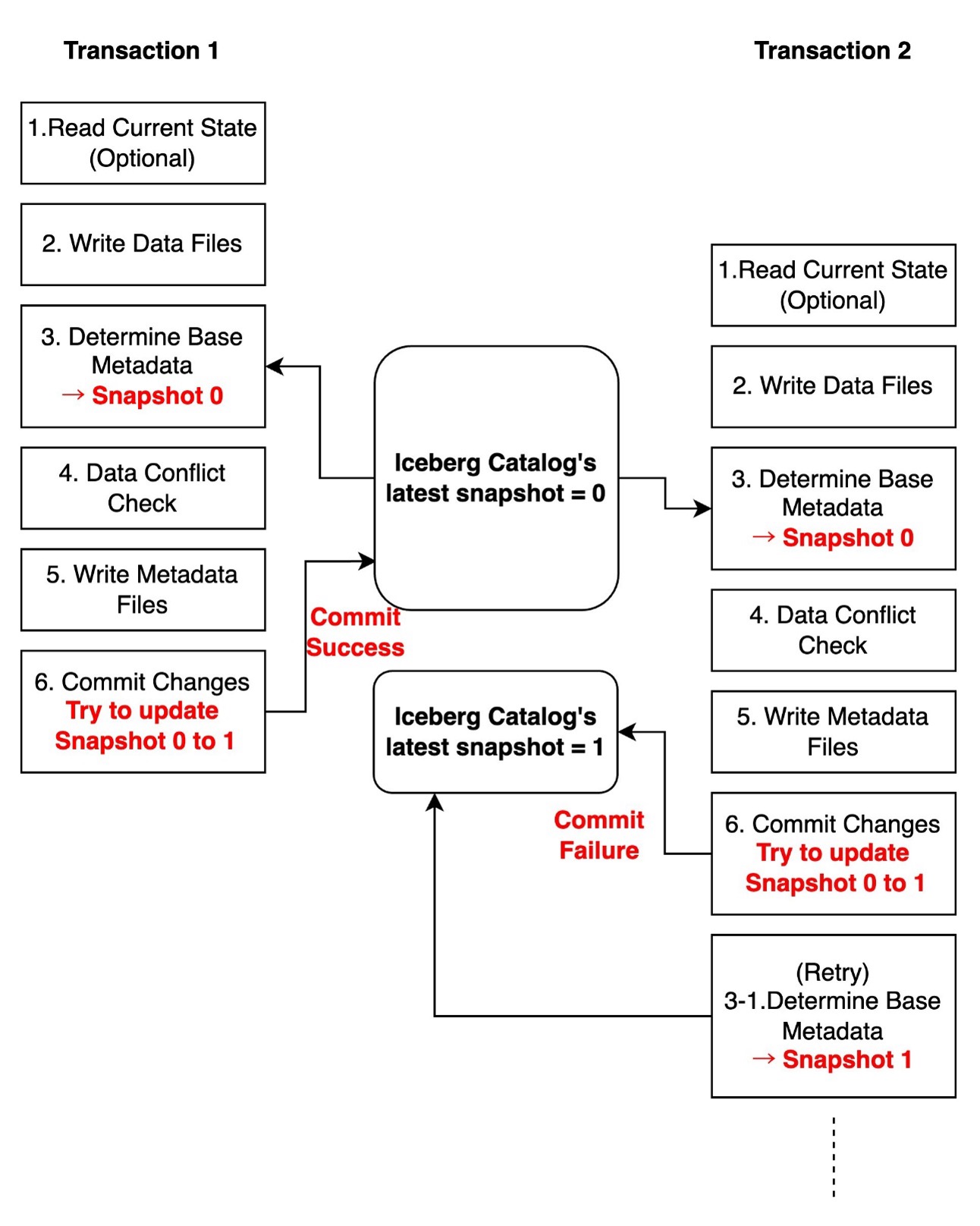
These conflicts are usually transient and may be routinely resolved via retries. You’ll be able to optionally configure write properties controlling commit retry conduct. For extra detailed configuration, check with Write properties within the Iceberg documentation.
The metadata used when studying the present state (Step 1) and the snapshot used as base metadata for updates (Step 3) may be completely different. Even when one other transaction updates the most recent snapshot between Steps 1 and three, the present transaction can nonetheless commit modifications to the catalog so long as it passes the info battle examine (Step 4). Which means even when computing modifications and writing knowledge recordsdata (Step 1 to 2) take a very long time, and different transactions make modifications throughout this era, the transaction can nonetheless try and decide to the catalog. This demonstrates Iceberg’s clever concurrency management mechanism.
The next diagram illustrates this workflow.

Information replace conflicts
Information replace conflicts are extra complicated and happen when concurrent transactions try to change overlapping knowledge. Throughout a write transaction, the question engine checks consistency between the snapshot being written and the most recent snapshot in accordance with transaction isolation guidelines. When incompatibility is detected, the transaction fails with a ValidationException.
Within the following diagram, two transactions run concurrently on an worker desk containing id, title, and wage columns. Transaction 1 makes an attempt to replace a document primarily based on Snapshot 0 and efficiently commits this alteration, making the most recent snapshot model 1. In the meantime, transaction 2 additionally makes an attempt to replace the identical document primarily based on Snapshot 0. When transaction 2 initially scanned the info, the most recent snapshot was 0, nevertheless it has since been up to date to 1 by transaction 1. In the course of the knowledge battle examine, transaction 2 discovers that its modifications battle with Snapshot 1, ensuing within the transaction failing.

These conflicts can’t be routinely retried by Iceberg’s library as a result of when knowledge conflicts happen, the desk’s state has modified, making it unsure whether or not retrying the transaction would keep total knowledge consistency. It’s good to deal with this sort of battle primarily based in your particular use case and necessities.
The next desk summarizes how completely different write patterns have various chance of conflicts.
| Write Sample | Catalog Commit Battle (Routinely retryable) | Information Battle (Non-retryable) |
| INSERT (AppendFiles) | Sure | By no means |
| UPDATE/DELETE with Copy-on-Write or Merge-on-Learn (OverwriteFiles) | Sure | Sure |
| Compaction (RewriteFiles) | Sure | Sure |
Iceberg desk’s isolation ranges
Iceberg tables help two isolation ranges: Serializable and Snapshot isolation. Each present a learn constant view of the desk and guarantee readers see solely dedicated knowledge. Serializable isolation ensures that concurrent operations run as in the event that they have been carried out in some sequential order. Snapshot isolation gives weaker ensures however affords higher efficiency in environments with many concurrent writers. Below snapshot isolation, knowledge battle checks can move even when concurrent transactions add new recordsdata with information that probably match its situations.
By default, Iceberg tables use serializable isolation. You’ll be able to configure isolation ranges for particular operations utilizing desk properties:
You have to select the suitable isolation stage primarily based in your use case. Notice that for conflicts between streaming ingestion and compaction operations, which is among the most typical situations, snapshot isolation doesn’t present any further advantages to the default serializable isolation. For extra detailed configuration, see IsolationLevel.
Implementation patterns
Implementing sturdy concurrent write dealing with in Iceberg requires completely different methods relying on the battle kind and use case. On this part, we share confirmed patterns for dealing with frequent situations.
Handle catalog commit conflicts
Catalog commit conflicts are comparatively easy to deal with via desk properties. The next configurations function preliminary baseline settings you can alter primarily based in your particular workload patterns and necessities.
For frequent concurrent writes (for instance, streaming ingestion):
For upkeep operations (for instance, compaction):
Handle knowledge replace conflicts
For knowledge replace conflicts, which might’t be routinely retried, you have to implement a customized retry mechanism with correct error dealing with. A typical state of affairs is when stream UPSERT ingestion conflicts with concurrent compaction operations. In such instances, the stream ingestion job ought to usually implement retries to deal with incoming knowledge. With out correct error dealing with, the job will fail with a ValidationException.
We present two instance scripts demonstrating a sensible implementation of error dealing with for knowledge conflicts in Iceberg streaming jobs. The code particularly catches ValidationException via Py4JJavaError dealing with, which is crucial for correct Java-Python interplay. It contains exponential backoff and jitter technique by including a random delay of 0–25% to every retry interval. For instance, if the bottom exponential backoff time is 4 seconds, the precise retry delay will likely be between 4–5 seconds, serving to forestall instant retry storms whereas sustaining cheap latency.
On this instance, we create a state of affairs with frequent MERGE operations on the identical information by utilizing 'worth' as a novel identifier and artificially limiting its vary. By making use of a modulo operation (worth % 20), we constrain all values to fall inside 0–19, which implies a number of updates will goal the identical information. For example, if the unique stream comprises values 0, 20, 40, and 60, they are going to all be mapped to 0, leading to a number of MERGE operations concentrating on the identical document. We then use groupBy and max aggregation to simulate a typical UPSERT sample the place we hold the most recent document for every worth. The reworked knowledge is saved in a brief view that serves because the supply desk within the MERGE assertion, permitting us to carry out UPDATE operations utilizing 'worth' because the matching situation. This setup helps exhibit how our retry mechanism handles ValidationExceptions that happen when concurrent transactions try to change the identical information.
The primary instance makes use of Spark Structured Streaming utilizing a fee supply with a 20-second set off interval to exhibit the retry mechanism’s conduct when concurrent operations trigger knowledge conflicts. Change amzn-s3-demo-bucket along with your S3 bucket title.
The second instance makes use of GlueContext.forEachBatch accessible on AWS Glue Streaming jobs. The implementation sample for the retry mechanism stays the identical, however the primary variations are the preliminary setup utilizing GlueContext and learn how to create a streaming DataFrame. Though our instance makes use of spark.readStream with a fee supply for demonstration, in precise AWS Glue Streaming jobs, you’ll usually create your streaming DataFrame utilizing glueContext.create_data_frame.from_catalog to learn from sources like Amazon Kinesis or Kafka. For extra particulars, see AWS Glue Streaming connections. Change amzn-s3-demo-bucket along with your S3 bucket title.
Reduce battle chance by scoping your operations
When performing upkeep operations like compaction or updates, it’s advisable to slender down the scope to attenuate overlap with different operations. For instance, think about a desk partitioned by date the place a streaming job repeatedly upserts knowledge for the most recent date. The next is the instance script to run the rewrite_data_files process to compact the complete desk:
By narrowing the compaction scope with a date partition filter within the the place clause, you possibly can keep away from conflicts between streaming ingestion and compaction operations. The streaming job can proceed to work with the most recent partition whereas compaction processes historic knowledge.
Conclusion
Efficiently managing concurrent writes in Iceberg requires understanding each the desk structure and numerous battle situations. On this publish, we explored learn how to implement dependable battle dealing with mechanisms in manufacturing environments.
Essentially the most vital idea to recollect is the excellence between catalog commit conflicts and knowledge conflicts. Though catalog commit conflicts may be dealt with via computerized retries and desk properties configuration, knowledge conflicts require cautious implementation of customized dealing with logic. This turns into notably necessary when implementing upkeep operations like compaction, the place utilizing the the place clause in rewrite_data_files can considerably decrease battle potential by lowering the scope of operations.
For streaming pipelines, the important thing to success lies in implementing correct error dealing with that may differentiate between battle sorts and reply appropriately. This contains configuring appropriate retry settings via desk properties and implementing backoff methods that align along with your workload traits. When mixed with well-timed upkeep operations, these patterns assist construct resilient knowledge pipelines that may deal with concurrent writes reliably.
By making use of these patterns and understanding the underlying mechanisms of Iceberg’s concurrency mannequin, you possibly can construct sturdy knowledge pipelines that successfully deal with concurrent write situations whereas sustaining knowledge consistency and reliability.
Concerning the Authors
 Sotaro Hikita is an Analytics Options Architect. He helps clients throughout a variety of industries in constructing and working analytics platforms extra successfully. He’s notably keen about large knowledge applied sciences and open supply software program.
Sotaro Hikita is an Analytics Options Architect. He helps clients throughout a variety of industries in constructing and working analytics platforms extra successfully. He’s notably keen about large knowledge applied sciences and open supply software program.
 Noritaka Sekiyama is a Principal Large Information Architect on the AWS Glue staff. He works primarily based in Tokyo, Japan. He’s chargeable for constructing software program artifacts to assist clients. In his spare time, he enjoys biking along with his street bike.
Noritaka Sekiyama is a Principal Large Information Architect on the AWS Glue staff. He works primarily based in Tokyo, Japan. He’s chargeable for constructing software program artifacts to assist clients. In his spare time, he enjoys biking along with his street bike.













{kind=link}