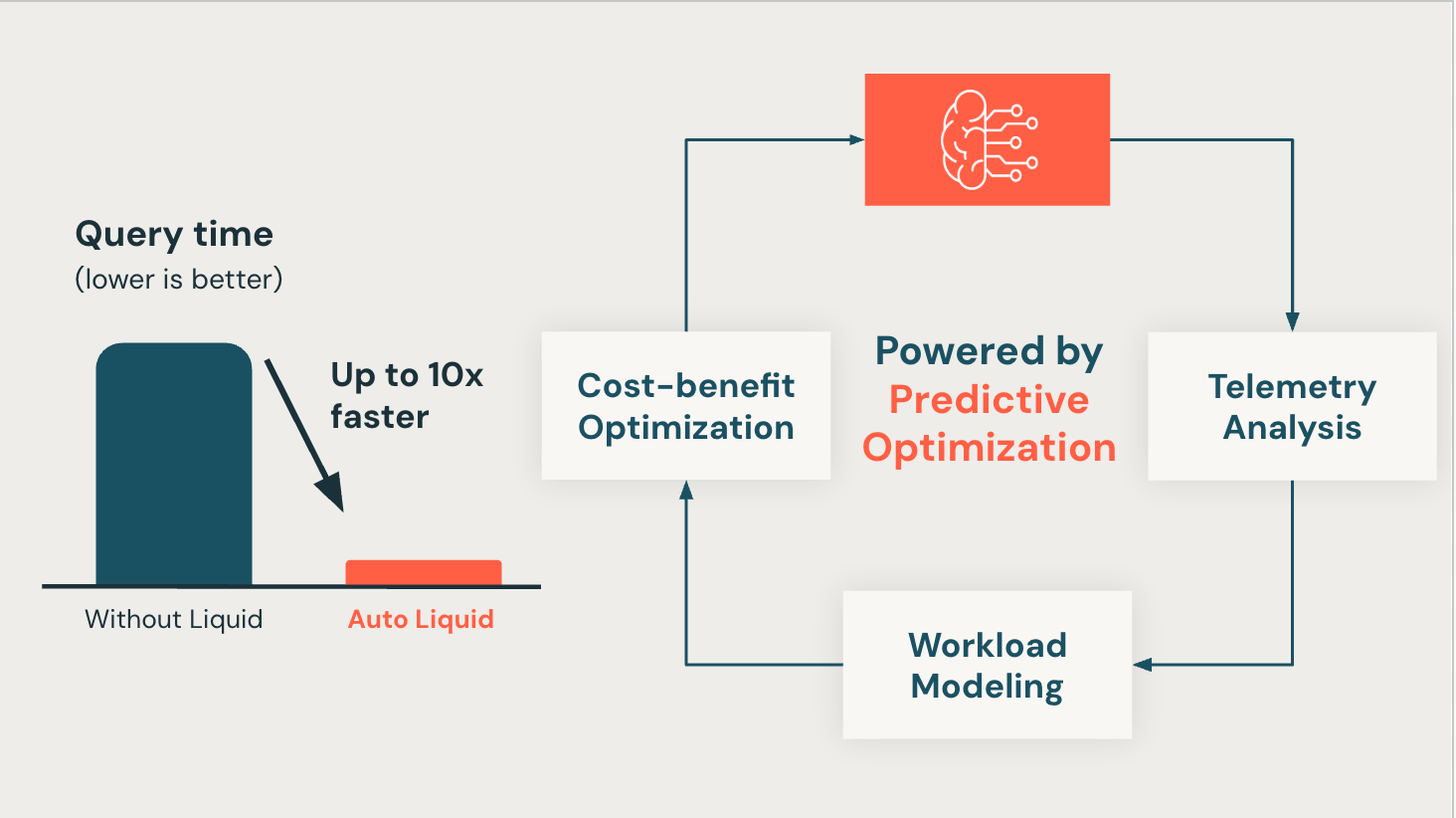


We’re excited to announce the Public Preview of Computerized Liquid Clustering, powered by Predictive Optimization. This characteristic routinely applies and updates Liquid Clustering columns on Unity Catalog managed tables, enhancing question efficiency and lowering prices.
Computerized Liquid Clustering simplifies knowledge administration by eliminating the necessity for handbook tuning. Beforehand, knowledge groups needed to manually design the particular knowledge format for every of their tables. Now, Predictive Optimization harnesses the ability of Unity Catalog to observe and analyze your knowledge and question patterns.
To allow Computerized Liquid Clustering, configure your UC managed unpartitioned or Liquid tables by setting the parameter CLUSTER BY AUTO.
As soon as enabled, Predictive Optimization analyzes how your tables are queried and intelligently selects the best clustering keys based mostly in your workload. It then clusters the desk routinely, guaranteeing knowledge is organized for optimum question efficiency. Any engine studying from the Delta desk advantages from these enhancements, resulting in considerably sooner queries. Moreover, as question patterns change, Predictive Optimization dynamically adjusts the clustering scheme, utterly eliminating the necessity for handbook tuning or knowledge format selections when establishing your Delta tables.
In the course of the Non-public Preview, dozens of consumers examined Computerized Liquid Clustering and noticed robust outcomes. Many appreciated its simplicity and efficiency positive factors, with some already utilizing it for his or her gold tables and planning to develop it throughout all Delta tables.
Preview clients like Healthrise have reported important question efficiency enchancment with Computerized Liquid Clustering:
“Now we have deployed Computerized Liquid Clustering to all our gold tables. Since then, our queries ran as much as 10x sooner. All our workloads have turn out to be way more environment friendly with none handbook work wanted in designing the information format or operating upkeep.”
— Li Zou, Principal Information Engineer , Brian Allee, Director, Information Companies | Know-how & Analytics, Healthrise
Selecting the very best knowledge format is a tough drawback
Making use of the very best knowledge format to your tables considerably improves question efficiency and value effectivity. Historically, with partitioning, clients have discovered it tough to design the best partitioning technique to keep away from knowledge skews and concurrency conflicts. To additional improve efficiency, clients would possibly use ZORDER atop partitioning, however ZORDERing is each costly and much more sophisticated to handle.
Liquid Clustering considerably simplifies knowledge layout-related selections and offers the pliability to redefine clustering keys with out knowledge rewrites. Prospects solely must select clustering keys purely based mostly on question entry patterns, with out having to fret about cardinality, key order, file dimension, potential knowledge skew, concurrency, and future entry sample adjustments. We have labored with 1000’s of consumers who benefited from higher question efficiency with Liquid Clustering, and we now have 3000+ lively month-to-month clients writing 200+ PB knowledge to Liquid-clustered tables per 30 days.
Nonetheless, even with the advances in Liquid Clustering, you continue to have to decide on the columns to cluster by based mostly on the way you question your desk. Information groups want to determine:
- Which tables will profit from Liquid Clustering?
- What are the very best clustering columns for this desk?
- What if my question patterns change as enterprise wants evolve?
Furthermore, inside a corporation, knowledge engineers usually must work with a number of downstream customers to grasp how tables are being queried, whereas additionally maintaining with altering entry patterns and evolving schemas. This problem turns into exponentially extra complicated as your knowledge quantity scales with extra analytics wants.
How Computerized Liquid Clustering evolves your Information Format
With Computerized Liquid Clustering, Databricks takes care of all knowledge layout-related selections for you – from desk creation, to clustering your knowledge and evolving your knowledge format – enabling you to give attention to extracting insights out of your knowledge.
Let’s see Computerized Liquid Clustering is in motion with an instance desk.
Take into account a desk example_tbl, which is continuously queried by date and buyer ID. It accommodates knowledge from Feb 5-6 and buyer IDs A to F. With none knowledge format configuration, the information is saved in insertion order, ensuing within the following format:
Suppose the shopper runs SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B'. The question engine leverages Delta knowledge skipping statistics (min/max values, null counts, and complete information per file) to establish the related recordsdata to scan. Pruning pointless file reads is essential, because it reduces the variety of recordsdata scanned throughout question execution, immediately enhancing question efficiency and reducing compute prices. The less recordsdata a question must learn, the sooner and extra environment friendly it turns into.
On this case, the engine identifies 5 recordsdata for Feb 5, as half of the recordsdata have a min/max worth for the date column matching that date. Nonetheless, since knowledge skipping statistics solely present min/max values, these 5 recordsdata all have a min/max customer_id that counsel buyer B is someplace within the center. In consequence, the question should scan all 5 recordsdata to extract entries for buyer B , resulting in a 50% file pruning price (studying 5 out of 10 recordsdata).
As you see, the core situation is that buyer B’s knowledge shouldn’t be colocated in a single file. Which means that extracting all entries for buyer B additionally requires studying a major quantity of entries for different clients.
Is there a method to enhance file pruning and question efficiency right here? Computerized Liquid Clustering can improve each. Right here’s how:
Behind the Scenes of Computerized Liquid Clustering: How It Works
As soon as enabled, Computerized Liquid Clustering constantly performs the next three steps:
- Amassing telemetry to find out if the desk will profit from introducing or evolving Liquid Clustering Keys.
- Modeling the workload to grasp and establish eligible columns.
- Making use of the column choice and evolving the clustering schemes based mostly on cost-benefit evaluation.

Step 1: Telemetry Evaluation
Predictive Optimization collects and analyzes question scan statistics, comparable to question predicates and JOIN filters, to find out if a desk would profit from Liquid Clustering.
With our instance, Predictive Optimization detects that the columns ‘date’ and ‘customer_id’ are continuously queried.
Step 2: Workload Modeling
Predictive Optimization evaluates the question workload and identifies the very best clustering keys to maximize knowledge skipping.
It learns from previous question patterns and estimates the potential efficiency positive factors of various clustering schemes. By simulating previous queries, it predicts how successfully every possibility would scale back the quantity of information scanned.
In our instance, utilizing registered scans on ‘date’ and ‘customer_id’ and assuming constant queries, Predictive Optimization calculates that:
- Clustering by
‘date’reads 5 recordsdata with 50% pruning charges. - Clustering by
‘customer_id’, reads ~2 recordsdata (an estimate) with an 80% pruning price.- Clustering by each
‘date’and‘customer_id’(see knowledge format beneath) reads simply 1 file with a 90% pruning price.
- Clustering by each
Step 3: Value-benefit Optimization
The Databricks Platform ensures that any adjustments to clustering keys present a transparent efficiency profit, as clustering can introduce extra overhead. As soon as new clustering key candidates are recognized, Predictive Optimization evaluates whether or not the efficiency positive factors outweigh the prices. If the advantages are important, it updates the clustering keys on Unity Catalog managed tables.
In our instance, clustering by ‘date’ and ‘customer_id’ leads to a 90% knowledge pruning price. Since these columns are continuously queried, the decreased compute prices and improved question efficiency justify the clustering overhead.
Preview clients have highlighted Predictive Optimization’s cost-effectiveness, significantly its low overhead in comparison with manually designing knowledge layouts. Corporations like CFC Underwriting have reported decrease complete price of possession and important effectivity positive factors.
“We actually love Databricks’ Computerized Liquid Clustering as a result of it offers us peace of thoughts that we have now essentially the most optimized knowledge format out-of-the-box. It additionally saved us a whole lot of time by eradicating the necessity for having an engineer to keep up the information format. Due to this functionality, we have now observed that our compute prices have gone down at the same time as we have scaled up our knowledge quantity.”
— Nikos Balanis, Head of Information Platform, CFC
The potential in a nutshell: Predictive Optimization chooses liquid clustering keys in your behalf, such that the anticipated price financial savings from knowledge skipping outweigh the anticipated price of clustering.
Get Began Immediately
When you haven’t enabled Predictive Optimization but, you are able to do so by deciding on Enabled subsequent to Predictive Optimization within the account console beneath Settings > Characteristic enablement.
New to Databricks? Since November eleventh, 2024, Databricks has enabled Predictive Optimization by default on all new Databricks accounts, operating optimizations for all of your Unity Catalog managed tables.
Get began in the present day by setting CLUSTER BY AUTO in your Unity Catalog managed tables. Databricks Runtime 15.4+ is required to CREATE new AUTO tables or ALTER present Liquid / unpartitioned tables. Within the close to future, Computerized Liquid Clustering will likely be enabled by default for newly created Unity Catalog managed tables. Keep tuned for extra particulars.










{kind=link}