Yongjun Zhang; Employees Software program Engineer | William Tom; Employees Software program Engineer | Sandeep Kumar; Software program Engineer | Hengzhe Guo; Software program Engineer |
Monarch, Pinterest’s Batch Processing Platform, was initially designed to help Pinterest’s ever-growing variety of Apache Spark and MapReduce workloads at scale. Throughout Monarch’s inception in 2016, essentially the most dominant batch processing know-how round to construct the platform was Apache Hadoop YARN. Now, eight years later, we’ve got made the choice to maneuver off of Apache Hadoop and onto our subsequent technology Kubernetes (K8s) based mostly platform. These are a number of the key points we purpose to handle:
You might also like


- Utility isolation with containerization: In Apache Hadoop 2.10, YARN purposes share the identical frequent surroundings with out container isolation. This typically results in exhausting to debug dependency conflicts between purposes.
- GPU help: Node labeling help was added to Apache Hadoop YARN’s Capability Scheduler (YARN-2496) and never Truthful Scheduler (YARN-2497), however at Pinterest we’re closely invested in Truthful Scheduler. Upgrading to a more moderen Apache Hadoop model with node labeling help in Truthful Scheduler or migrating to Capability Scheduler would require great engineering effort.
- Hadoop improve effort: In 2020, we upgraded from Apache Hadoop 2.7 to 2.10. This minor model improve course of took roughly one yr. A serious model improve to three.x will take us considerably extra time.
- Hadoop group help: The business as a complete has been shifting to K8s and Apache Hadoop is essentially in upkeep mode.
Over the previous few years, we’ve noticed widespread business adoption of K8s to handle these challenges. After a prolonged inner proof of idea and analysis we made the choice to construct out our subsequent technology K8s-based platform: Moka (Monarch on K8s).
On this weblog, we’ll be overlaying the challenges and corresponding options that allow us emigrate hundreds of Spark purposes from Monarch to Moka whereas sustaining useful resource effectivity and a top quality of service. You possibly can try our earlier weblog, which describes how Monarch assets are managed effectively to attain value saving whereas guaranteeing job stability. On the time of scripting this weblog, we’ve got migrated half of the Spark workload working on Monarch to Moka. The remaining MapReduce jobs working on Monarch are actively being migrated to Spark as a part of a separate initiative to deprecate MapReduce inside Pinterest.
Our aim with Moka useful resource administration was to retain the optimistic properties of Monarch’s useful resource administration and enhance upon its shortcomings.
First, let’s cowl the issues that labored nicely on Monarch that we wished to convey over to Moka:
- Associating every workflow with its proprietor’s group and challenge
- Classifying all workflows into three tiers: tier 1 (highest precedence), tier 2, and tier 3, and defining the runtime SLO for every workflow
- Utilizing hierarchical org-base-queue (OBQ) within the format of
root.. for useful resource allocation and workload scheduling. - Monitoring per-application runtime knowledge, together with the appliance’s begin and finish time, reminiscence and vCore utilization, and so forth.
- Environment friendly tier-based useful resource allocation algorithms that robotically modify OBQs based mostly on the historic useful resource utilization of the workflows assigned to the queues
- Providers that may route workloads from one cluster to a different, which we name cross-cluster-routing (CCR), to their corresponding OBQs
- Onboarding queues with reserved assets to onboard new workloads
- Periodic useful resource allocation processes handle OBQs from the useful resource utilization knowledge collected through the onboarding queue runs
- Dashboards to watch useful resource utilization and workflow runtime SLO efficiency
Step one to programmatically migrating workloads from Monarch to Moka at scale is useful resource allocation. Many of the gadgets listed above may be re-used as-is or simply prolonged to help Moka. Nevertheless, there are a couple of further gadgets that we would want to help useful resource allocation on Moka:
- A scheduler that’s application-aware, permits managing cluster assets as hierarchical queues, and helps preemption
- A pipeline to export useful resource utilization data for all purposes run on Moka and ingestion pipelines to generate perception tables
- A useful resource allocation job that makes use of the insights tables to generate the OBQ useful resource allocation
- An orchestration layer that is ready to route workloads to their goal clusters and OBQs
Now let’s go into element on how we solved these 4 lacking items.
The default K8s scheduler is a “jack of all trades, grasp of none” resolution that isn’t notably adept at scheduling batch processing workloads. For our useful resource scheduling wants, we would have liked a scheduler that helps hierarchical queues and is ready to schedule on a per-application and per-user foundation as an alternative of per-pod foundation.
Apache YuniKorn is designed by a gaggle of engineers with deep expertise engaged on Apache Hadoop YARN and K8s. Apache YuniKorn not solely acknowledges customers, purposes, and queues, but in addition contains many different components, resembling ordering, priorities, and preemption when making scheduling selections.
Provided that Apache YuniKorn has essentially the most attributes we’d like, we determined to make use of it in Moka.
As talked about earlier, software useful resource utilization historical past is important for the way we do useful resource allocation. At a excessive degree, we use the historic utilization of a queue as a baseline to estimate how a lot needs to be allotted going ahead in every iteration of the allocation course of. Nevertheless, once we made the choice to first undertake Apache YuniKorn it was lacking this very important characteristic. Apache YuniKorn was completely stateless and solely tracked instantaneous useful resource utilization throughout the cluster.
We would have liked an answer that will be capable to reliably observe useful resource consumption of all pods belonging to an software and was fault tolerant. For this, we labored intently with the Apache YuniKorn group so as to add help for logging useful resource utilization data for completed purposes (see YUNIKORN-1385 for extra data). This characteristic aggregates pod useful resource utilization per software and experiences a ultimate useful resource utilization abstract upon software completion.
This abstract is logged to Apache YuniKorn’s stdout the place we use Fluent Bit to filter out the app abstract logs and write them to S3.
By design, the Apache YuniKorn software abstract comprises comparable data as YARN’s software abstract produced by YARN ResourceManager (see extra particulars on this doc) in order that it will match seamlessly into current customers of YARN software summaries.
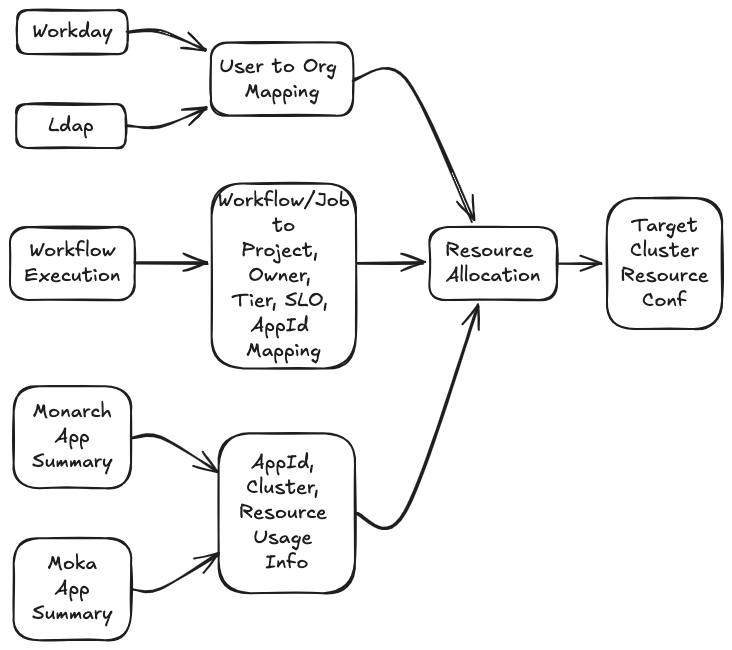
Along with software useful resource utilization data, the next mapping data is robotically ingested into the perception tables:
- Workflow to challenge, tier, SLO
- Undertaking to proprietor
- Proprietor to firm group
- Workflow job to purposes
This data is used for associating workloads with their goal queue and estimating the queue’s future useful resource necessities.
Determine 1 reveals the knowledge ingestion and useful resource allocation circulation.
To study extra in regards to the useful resource allocation algorithm, see our earlier weblog put up: Environment friendly Useful resource Administration at Pinterest’s Batch Processing Platform.
Our algorithm prioritizes useful resource allocation to tier 1 and tier 2 queues as much as a specified percentile threshold of the queue’s required assets.
One draw back to this strategy is that it typically requires a number of iterations of useful resource allocation to converge to a steady one, the place every iteration requires some guide tuning of parameters.
As a part of the Moka migration, we designed and carried out a model new algorithm that leverages Constraint Programming Utilizing CP-SAT from the OR-Instruments open supply suite for optimization. This device generates a mannequin by setting up a set of constraints based mostly on the utilization/capability ratio hole between excessive tier (tier 1 and a pair of) and low tier (tier 3) useful resource requests. This new useful resource allocation algorithm runs sooner and extra reliably with out human intervention.
Our job submission layer, Archer, is accountable for dealing with all job submissions to Moka. Archer supplies flexibility on the platform degree to investigate, modify and route jobs at submission time. This contains routing jobs to particular Moka clusters and queues.
Determine 2 reveals how we do useful resource allocation with CCR for choose jobs and the deployment course of. The useful resource allocation change made at git repo is robotically submitted to Archer, and Archer talks to k8s to deploy the modified useful resource allocation config map, after which route jobs at runtime based mostly on the CCR guidelines arrange within the Archer Routing DB.
We plan to cowl Archer and Moka in future weblog posts.
Along with YUNIKORN-1385, listed here are another options and fixes we contributed again to the Apache YuniKorn group.
- YUNIKORN-790: Provides help for maxApplications to restrict the variety of purposes that may run concurrently in any queue
- YUNIKORN-2030: Fixes a bug when checking headroom which causes Apache YuniKorn to stall
- YUNIKORN-970 Add queue metrics with queue names as tags to make queue metrics simpler to trace and look at
- YUNIKORN-1948 Introduce a command to validate the content material of a given queue config file
Apache YuniKorn continues to be a comparatively younger open supply challenge, and we’re persevering with to work with the group collectively to complement its performance and enhance its reliability and effectivity.
As soon as we began to onboard actual manufacturing workloads to Moka, we prolonged our current Workflow SLO Efficiency Dashboards for Monarch to incorporate the every day runtime outcomes of apps working on Moka. Our aim is to make sure no less than 90% of tier 1 workflows meet their SLO no less than 90% of time.
Regardless of having made nice progress constructing out the Moka platform and migrating jobs from our legacy platform there are nonetheless many enhancements we’ve got deliberate. To present you a teaser of what’s to return:
We’re within the strategy of designing a stateful service that is ready to leverage YUNIKORN-1628 and YUNIKORN-2115 which introduce occasion streaming help.
As well as, we’re engaged on a full-featured useful resource administration console to handle the platform assets. This console will allow platform directors to watch cluster and queue useful resource utilization in actual time and permits customized load balancing between clusters.
To start with, due to the Apache YuniKorn group for his or her help and collaboration once we have been evaluating Apache YuniKorn and for working with us to submit patches we made internally again to the open supply challenge.
Subsequent, due to our good teammates, Rainie Li, Hengzhe Guo, Soam Acharya, Bogdan Pisica, Aria Wang from the Batch Processing Platform and Knowledge Processing Infra groups for his or her work on Moka. Thanks Ang Zhang, Jooseong Kim, Chen Qin, Soam Acharya, Chunyan Wang et al for his or her help and insights whereas we have been engaged on the challenge.
Final however not least, thanks to the Workflow Platform crew and the entire consumer groups of our platform for his or her suggestions.
To study extra about engineering at Pinterest, try the remainder of our Engineering Weblog and go to our Pinterest Labs website. To discover and apply to open roles, go to our Careers web page.










{kind=link}