You might also like


Zhibo Fan | Machine Studying Engineer, Homefeed Candidate Technology; Bowen Deng | Machine Studying Engineer, Homefeed Candidate Technology; Hedi Xia | Machine Studying Engineer, Homefeed Candidate Technology; Yuke Yan | Machine Studying Engineer, Homefeed Candidate Technology; Hongtao Lin | Machine Studying Engineer, ATG Utilized Science; Haoyu Chen | Machine Studying Engineer, ATG Utilized Science; Dafang He | Machine Studying Engineer, Homefeed Relevance; Jay Adams | Principal Engineer, Pinner Curation & Development; Raymond Hsu | Engineering Supervisor, Homefeed CG Product Enablement; James Li | Engineering Supervisor, Homefeed Candidate Technology; Dylan Wang | Engineering Supervisor, Homefeed Relevance
At Pinterest Homefeed, embedding-based retrieval (a.okay.a Discovered Retrieval) is a key candidate generator to retrieve extremely customized, participating, and numerous content material to satisfy varied person intents and allow a number of actionability, resembling Pin saving and buying. We’ve launched the institution of this two-tower mannequin with its modeling fundamentals and serving particulars. On this weblog, we’ll concentrate on the enhancements we made on embedding-based retrieval: how we scale up with superior characteristic crossing and ID embeddings, upgrading the serving corpus, and our present journey to machine studying primarily based retrieval revolution with state-of-the-art modeling.
We’ve varied options supplied to the mannequin within the hope that it may possibly reveal the latent sample for person engagements, starting from pretrained embedding options to categorical or numerical options. All these options are transformed to dense representations via embedding or Multi-layer perceptron (MLP) layers. A previous data of advice duties is that incorporating extra characteristic crossing might profit mannequin efficiency. For instance, understanding the mixture of film creator and style supplies extra context than having these options alone.
The widespread philosophy for two-tower fashions is modeling simplicity; nonetheless, it’s extra about having no user-item characteristic interplay and utilizing easy similarity metrics like dot-product. As a result of the Pin tower is used offline and the person tower is barely fetched as soon as throughout a homefeed request, we will scale as much as an advanced mannequin construction inside every tower. All the next buildings are utilized to each towers.
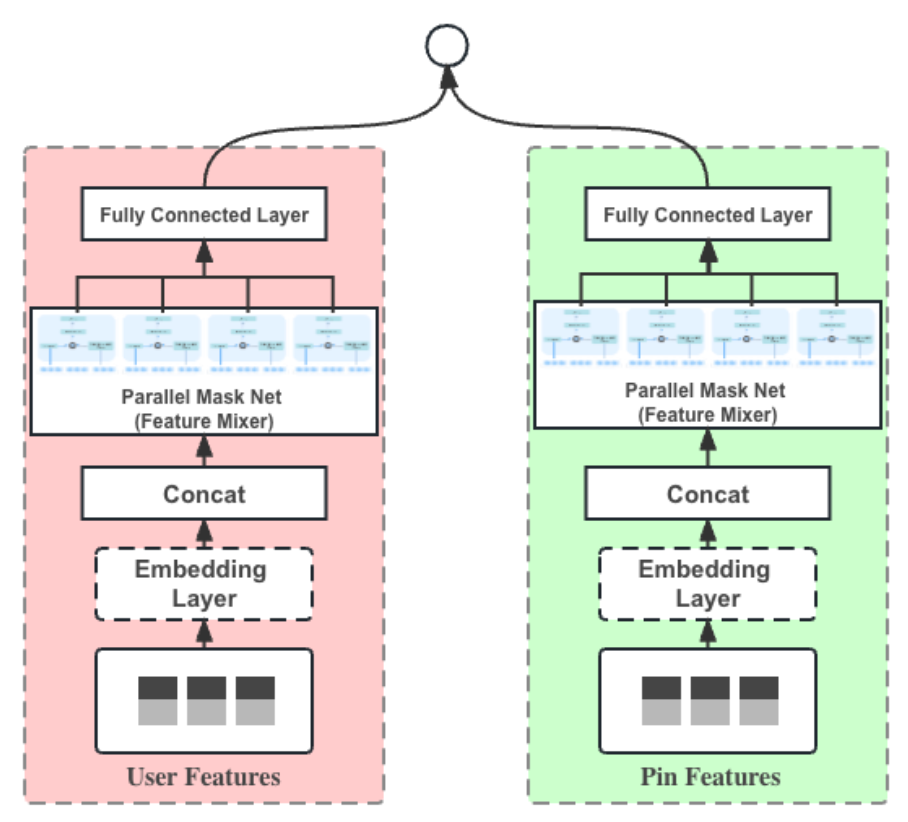
Our first try is to improve the mannequin with MaskNet[1] for bitwise characteristic crossing. This course of is completely different from the unique paper: after embedding layer normalization and concatenation, our MaskNet block is carried out because the Hadamard product of the enter embedding and a projection of itself by way of a two-layer MLP, adopted by one other two-layer MLP to refine the illustration. We parallelize 4 such blocks with a bottleneck-style MLP. This setup simplifies the mannequin structure and brings excessive learnability with intensive characteristic crossing inside every tower. At Pinterest Homefeed, we use engaged periods to measure the affect of advice system iterations, that are steady interplay periods bigger than 60 seconds. This mannequin structure improve improved 0.15–0.35% engaged periods throughout Pinterest.
We additional upscale the structure to the DHEN[2] framework, which ensembles a number of completely different characteristic crossing layers in each serial and parallel methods. We juxtapose an MLP layer with the identical parallel masks web and append one other layer of juxtaposition of an MLP and a transformer encoder[3]. This appended layer enhances field-wise interplay for the reason that consideration is utilized at discipline stage, whereas the dot-product primarily based characteristic crossing is at bit stage for MaskNet. This scaling up brings one other +0.1–0.2% engaged periods, along with >1% homefeed saves and clicks.
Business suggestion exhibits the good thing about having ID embeddings by memorizing person engagement patterns. At Pinterest, to beat the well-known ID embedding overfitting situation and maximize ROI and suppleness in downstream ML fashions, we pre-train large-scale person and Pin ID embeddings by contrastive studying on sampled negatives over a cross-surface massive window dataset with no constructive engagement downsampling [7]. It brings nice ID protection and wealthy semantics tailor-made for suggestions at Pinterest. We undertake this massive ID embedding desk within the retrieval mannequin to reinforce the precision. At coaching time, we use the lately launched torchrec library to implement and shared the massive pin ID desk throughout GPUs. We serve the CPU mannequin artifact as a result of unfastened latency requirement for offline inference.
Nevertheless, though the coaching goals for the 2 fashions are related (i.e., contrastive studying over sampled negatives), straight fine-tuning the embeddings does carry out nicely on-line. We discovered that the mannequin suffered from overfitting severely. To mitigate this, we first mounted the embedding desk and utilized an aggressive dropout with dropout chance of 0.5 on prime of the ID embeddings, which led to respectable on-line beneficial properties (0.6–1.2% HF repins and clicks improve). Later, we discovered it isn’t optimum to easily use the most recent pretrained ID embedding, because the overlap between cotraining window and mannequin coaching window can worsen overfitting. We ended up selecting the most recent ID embedding with out overlap, offering 0.25–0.35% HF repins improve.
Other than mannequin upgrades, we additionally renovate our serving corpus because it defines the upper-limit of retrieval efficiency. Our preliminary corpus setup was to individualize Pins primarily based on their canonical picture signature, then embrace Pins with probably the most gathered engagements within the final 90 days. To raised seize the developments at Pinterest, as an alternative of straight summing over the engagements, we change to a time decayed summation to find out the rating of a Pin p at date d as:
As well as, we additionally discovered a discrepancy in picture signature granularity between coaching knowledge and serving corpus. Serving corpus operates on a extra coarse granularity to deduplicate related contents and scale back indexing measurement; nonetheless, it’s going to trigger statistical options drifting, resembling Pin engagements as a result of the seemed up picture signature is completely different in comparison with coaching knowledge. Closing this hole with a devoted picture signature remapping logic plus the time decay heuristics, we achieved +0.1–0.2% engaged periods with none modeling adjustments.
On this part, we’ll briefly showcase our latest journey to bootstrapping the affect of embedding-based retrieval with state-of-the-art modeling methods.
Completely different from different surfaces, homefeed has customers getting into with numerous intents, and it may be insufficient to signify all types of intents by a single embedding. With intensive experiments, we discovered {that a} differentiable clustering module modified upon Capsule Networks[4][5] performs higher than different variants resembling multi-head consideration and pre-clustering primarily based strategies. We switched the cluster initialization with maxmin initialization[6] to hurry up clustering convergence, and implement single-assignment routing the place every historical past merchandise can solely contribute to 1 cluster’s embedding to reinforce diversification. We mix every of the cluster embeddings with different person options to generate a number of embeddings.
At serving time, we solely hold the primary Okay embeddings and run ANN search, and Okay is decided by the size of person historical past. Due to the property of maxmin initialization, the primary Okay embeddings are usually probably the most consultant ones. Then the outcomes are mixed in a spherical robin style and handed to the rating and mixing layers. This new person sequence modeling method not solely hones range of the system but additionally helps improve customers’ save actions, indicating that customers refine their inspiration on homefeed.
At Pinterest, an awesome supply of range comes from the curiosity feed candidate generator, a token-based search in accordance with customers’ specific adopted pursuits and inferred pursuits. These specific curiosity alerts might present us with auxiliary data on the person’s intentions past person engagement historical past. Nevertheless, because of lack of finer-grained personalization among the many matched candidates, they have a tendency to have decrease engagement charge.
We utilized conditional retrieval[8], a two-tower mannequin with a conditional enter to spice up personalization and engagements: at coaching time, we feed the goal Pin’s curiosity id and embed it because the situation enter to the person tower; once we serve the mannequin, we feed customers’ adopted and inferred pursuits because the conditional enter to fetch the candidates. The mannequin follows an early-fusion paradigm that the conditional curiosity enter is fed into the mannequin on the identical layer as all different options. Surprisingly, the mannequin can be taught to situation its output and produce extremely related outcomes, even among the many long-tail pursuits. We additional geared up the ANN search with curiosity filters to ensure excessive relevance between the question curiosity and the retrieved candidates. Having higher personalization and engagements on the retrieval stage helps enhance suggestion funnel effectivity and improves person engagements considerably.
This weblog represents quite a lot of workstreams on embedding-based retrieval throughout many groups at Pinterest. We need to thank them for the precious assist and collaboration.
Dwelling Relevance: Dafang He, Alok Malik
ATG: Yi-Ping Hsu
PADS: Lily Ling
Pinner Curation & Development: Jay Adams










{kind=link}