You might also like


Charles Wu, Software program Engineer | Isabel Tallam, Software program Engineer | Franklin Shiao, Software program Engineer | Kapil Bajaj, Engineering Supervisor
Suppose you simply noticed an fascinating rise or drop in certainly one of your key metrics. Why did that occur? It’s a straightforward query to ask, however a lot tougher to reply.
One of many key difficulties to find root causes for metric actions is that these causes can are available all sizes and shapes. For instance, in case your metric dashboard reveals customers experiencing increased latency as they scroll by their dwelling feed, then that may very well be brought on by something from an OS improve, a logging or information pipeline error, an unusually giant enhance in person visitors, a code change landed just lately, and many others. The doable causes go on and on.
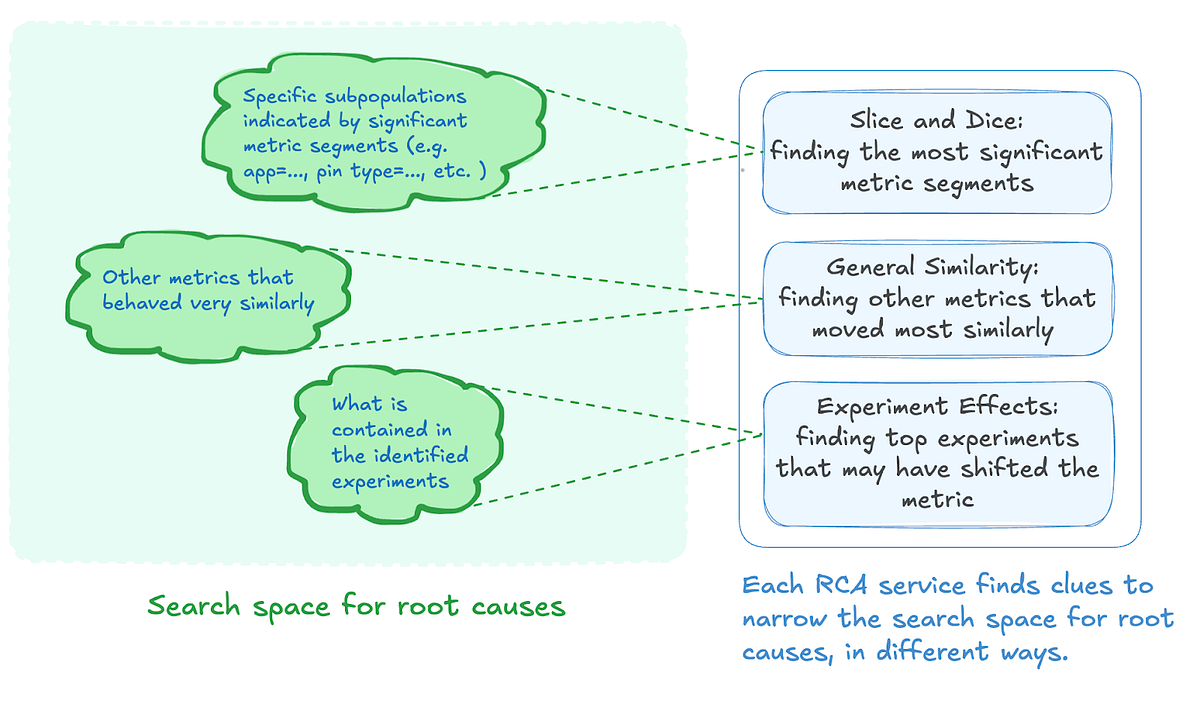
At Pinterest, now we have constructed completely different quantitative fashions to grasp why metrics transfer the best way they do. This weblog outlines the three pragmatic approaches that kind the premise of the root-cause evaluation (RCA) platform at Pinterest. As you will notice, all three approaches attempt to slender down the search house for root causes in numerous methods.
This strategy finds clues for a metric motion by drilling down on particular segments inside the metric; it has discovered successes at Pinterest, particularly in diagnosing video metric regressions.
For instance, suppose we’re monitoring video view charge (i.e., variety of views over impressions). At Pinterest, a metric like video view charge is multidimensional: it has many dimensions like nation, gadget sort, Pin sort, floor, streaming sort, and many others., that specify which subset of customers the metric is describing. Utilizing the completely different dimensions, we will break down the top-line metric into finer metric segments, every section equivalent to a mix of dimension values. We’re concerned about figuring out essentially the most important segments which have both considerably contributed to a top-line metric motion or have exhibited very uncommon actions themselves not mirrored within the top-line.
How we’re analyzing the metric segments takes inspiration from the algorithm in Linkedin’s ThirdEye. We arrange the completely different metric segments right into a tree construction, ordered by the scale we’re utilizing to segmentize the metric. Every node within the tree corresponds to a doable metric section.
Relying in your use-case, you would then outline your personal heuristics when it comes to the completely different elements that decide the importance of a metric section, within the context of its dad or mum section and/or the top-line metric. You might then synthesize the elements into an general significance rating.
The LinkedIn weblog already listed a number of elements that we discovered helpful, together with what number of information factors a metric section represents, in addition to how “sudden” the metric section’s motion is between what’s noticed and what’s anticipated, particularly in comparison with its dad or mum section within the tree.
Listed here are some further recommendations based mostly on our expertise that you would strive:
- Attempt tweaking how the elements are calculated; e.g., for every metric section, what are the “noticed” and “anticipated” values? Are they values taken at two discrete deadlines or averages/percentiles of information from two time home windows (i.e., one baseline window and one window wherein the anomalous top-line metric motion occurred)? Equally, the metric section dimension issue is also aggregated from a time window.
- Add new elements that make sense on your use-case; e.g., an element like how nicely a metric section correlates with the dad or mum section / top-line metric within the time window of curiosity.
- Modify the weights of the various factors over time based mostly on continued evaluations.
Notice that for every metric section (i.e. every node within the tree) it’s essential choose sufficient information to calculate all of the elements. Loads of OLAP databases assist SQL options (e.g., GROUP BY ROLLUP) that may get the info for all metric segments. As soon as the section tree is constructed, you may as well select to drill down ranging from any metric section because the top-line.
Lastly, be aware that the tree construction implies an order or hierarchy within the dimensions we’re slicing every time. Whereas some dimensions can certainly relate to at least one one other in clear hierarchical order (e.g., dimensions nation and state), others can not (e.g., dimensions nation and gadget sort). Have a look at it this manner: if this drill-down investigation have been guide, the investigator would nonetheless have to decide on an order of dimensions to slice alongside every time, from context or expertise. The hierarchy within the tree construction captures that.
On this strategy, we search for clues of why a metric motion occurred by scanning by different metrics and discovering ones which have moved very “equally” in the identical time interval, whether or not in the identical course (constructive affiliation) or in the other way (unfavourable affiliation).
To measure the similarity of metric actions, we use a synthesis of 4 various factors:
- Pearson correlation: measures the energy of the linear relationship between two time-series
- Spearman’s rank correlation: measures the energy of the monotonic relationship (not simply linear) between two time-series; in some circumstances, that is extra sturdy than Pearson’s correlation
- Euclidean similarity: outputs a similarity measure based mostly on inversing the Euclidean distance between the 2 (standardized) time-series at every time level
- Dynamic time warping: whereas the above three elements measure similarities between two time-series in time home windows of the identical size (normally the identical time window), this helps evaluating metrics from time home windows of various lengths based mostly on the gap alongside the trail that the 2 time-series greatest align
In apply, now we have discovered that the primary two elements, Pearson and Spearman’s rank correlations, work greatest as a result of:
- p-values could be computed for each, which assist to gauge statistical significance
- each have extra pure assist for measuring unfavourable associations between two time-series
- non-monotonic (e.g. quadratic) relationships, for which Pearson and Spearman’s rank correlations gained’t apply, don’t are inclined to come up naturally to date in our use-cases / time window of research
At Pinterest, one of many notable makes use of for this RCA performance has been to find the connection between efficiency metrics and content material distribution. Some kinds of Pins are extra “costly” to show, useful resource clever, than others (e.g., video Pins are dearer than static picture Pins), so may or not it’s that the latency customers skilled has elevated as a result of they noticed dearer Pins and fewer cheap ones as they scroll by their dwelling feed or search feed? RCA has offered the preliminary statistical alerts that efficiency regressions and content material shifts may certainly be linked, motivating additional investigations to estimate the precise causal results.
It’s essential to needless to say this RCA strategy relies on analyzing correlations and distances, which don’t indicate causation. The stronger statistical proof for causation is after all established by experiments, which we’ll flip our consideration to subsequent.
This third strategy appears to be like for clues of why metric actions occurred by taking a look at what loads of web firms have: experiments.
An experiment performs A/B testing to estimate the impact of a brand new characteristic. In an experiment, a portion of the customers are randomly assigned to both a management or a remedy group, and those within the remedy group expertise a brand new characteristic (e.g., a brand new suggestion algorithm). The experimenter sees if there’s a statistically important distinction in some key metrics (e.g., elevated person engagement) between the management and the remedy group.
In RCA, we carry out the above in reverse: given a metric, we wish to see which experiments have shifted that metric essentially the most, whether or not supposed or not.
Every person request to RCA specifies the metric, section, and time window the person is concerned about. Then, RCA calculates every experiment’s impression on the metric section over the course of that point window and ranks the highest experiments by impression. The RCA calculation and rating are carried out dynamically per person request and are not a part of a pre-computation pipeline (though the method might depend on some pre-aggregated information); this helps analyzing the impacts for a most quantity of metrics, typically on an ad-hoc foundation, with out leading to a scientific enhance in computation or storage price.
For every management and remedy group in an experiment, we carry out a Welch’s t-test on the remedy impact, which is strong within the sense that it helps unequal variances between management and remedy teams. To additional fight noise within the outcomes, we filter experiments by every experiment’s harmonic imply p-value of its remedy results over every day within the given time interval, which helps restrict false constructive charges. We additionally detect imbalances in management and remedy group sizes (i.e., when they’re being ramped up at a unique charge from one another) and filter out circumstances when that occurs.
We’ve got built-in RCA Experiment Results with the experimentation platform at Pinterest. With in depth application-level caching, in addition to some question optimizations, we’re in a position to have RCA dynamically discover the highest experiments affecting all metrics lined by the experimentation platform — near 2000 of them on the time of writing, together with a wide range of system, person engagement, and belief and security metrics.
All three RCA providers may very well be used collectively iteratively, as illustrated beneath.
What’s offered listed below are simply three approaches to narrowing down the search house of root-causes of metric actions. There are different methods of doing this, which we’ll discover and add as calls for come up.
For analytics instruments like anomaly detection or root-cause evaluation, the outcomes are sometimes mere recommendations for customers who might not have a transparent concept of the algorithms concerned or how one can tune them. Subsequently, it could be good to have an efficient suggestions mechanism wherein the customers may label the outcomes as useful or not, and that suggestions is routinely taken under consideration by the algorithm going ahead.
One other potential space of enchancment that we’re wanting into is leveraging causal discovery to be taught the causal relationships between completely different metrics. This is able to hopefully present richer statistical proof for causality with much less noise, in comparison with the present RCA Common Similarity.
As we enhance the RCA providers’ algorithms, we might additionally wish to combine them with extra information platforms inside Pinterest and make RCA readily accessible by the platforms’ respective net UIs. For instance, we’re exploring integrating RCA into the info exploration and visualization platforms at Pinterest.
We’re extremely grateful to the engineers and information scientists at Pinterest, who’ve been enthusiastic in attempting and adopting the completely different RCA providers and providing their precious suggestions.










{kind=link}