

Generative AI is reworking how organizations work together with their information, and batch LLM processing has shortly develop into one among Databricks’ hottest use circumstances. Final 12 months, we launched the primary model of AI Capabilities to allow enterprises to use LLMs to non-public information—with out information motion or governance trade-offs. Since then, 1000’s of organizations have powered batch pipelines for classification, summarization, structured extraction, and agent-driven workflows. As generative AI workloads transfer into manufacturing, pace, scalability, and ease have develop into important.
That’s why, as a part of our Week of Brokers initiative, we’ve rolled out main updates to AI Capabilities, enabling them to energy production-grade batch workflows on enterprise information. AI features—whether or not general-purpose (ai_query() for versatile prompts) or task-specific (ai_classify(), ai_translate())— are actually absolutely serverless and production-grade, requiring zero configuration and delivering over 10x quicker efficiency. Moreover, they’re now deeply built-in into the Databricks Information Intelligence Platform and accessible instantly from notebooks, Lakeflow Pipelines, Databricks SQL, and even Databricks AI/BI.
What’s New?
- Utterly Serverless – No endpoint setup & no infrastructure administration. Simply run your question.
- Sooner Batch Processing – Over 10x pace enchancment with our production-grade Mosaic AI Basis Mannequin API Batch backend.
- Simply extract structured insights – Utilizing our Structured Output characteristic in AI Capabilities, our Basis Mannequin API extracts insights in a construction you specify. No extra “convincing” the mannequin to offer you output within the schema you need!
- Actual-Time Observability – Observe question efficiency and automate error dealing with.
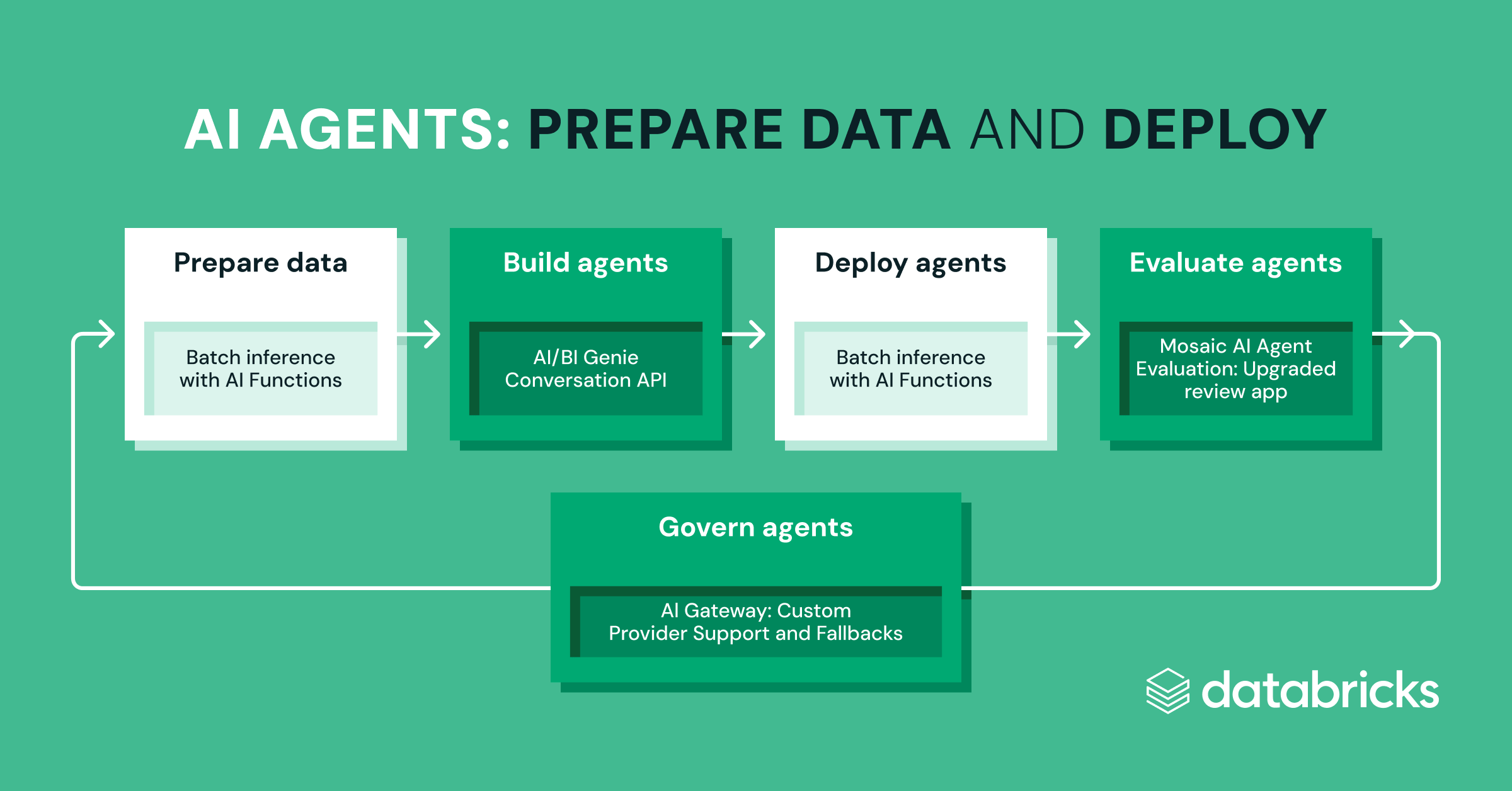
- Constructed for Information Intelligence Platform – Use AI Capabilities seamlessly in SQL, Notebooks, Workflows, DLT, Spark Streaming, AI/BI Dashboards, and even AI/BI Genie.
Databricks’ Strategy to Batch Inference
Many AI platforms deal with batch inference as an afterthought, requiring guide information exports and endpoint administration that end in fragmented workflows. With Databricks SQL, you’ll be able to take a look at your question on a pair rows with a easy LIMIT clause. In case you notice you would possibly need to filter on a column, you’ll be able to simply add a WHERE clause. After which simply take away the LIMIT to run at scale. To those that often write SQL, this may occasionally appear apparent, however in most different GenAI platforms, this may have required a number of file exports and customized filtering code!
Upon getting your question examined, operating it as a part of your information pipeline is so simple as including a activity in a Workflow and incrementalizing it’s straightforward with Lakeflow. And if a special person runs this question, it’ll solely present the outcomes for the rows they’ve entry to in Unity Catalog. That’s concretely what it implies that this product runs instantly throughout the Information Intelligence Platform—your information stays the place it’s, simplifying governance, and slicing down the trouble of managing a number of instruments.
You should utilize each SQL and Python to make use of AI Capabilities, making Batch AI accessible to each analysts and information scientists. Prospects are already having success with AI Capabilities:
“Batch AI with AI Capabilities is streamlining our AI workflows. It is permitting us to combine large-scale AI inference with a easy SQL query-no infrastructure administration wanted. This can instantly combine into our pipelines slicing prices and lowering configuration burden. Since adopting it we have seen dramatic acceleration in our developer velocity when combining conventional ETL and information pipelining with AI inference workloads.”
— Ian Cadieu, CTO, Altana
Working AI on buyer help transcripts is so simple as this:
Or making use of batch inference at scale in Python:
Deep Dive into the Newest Enhancements
1. On the spot, Serverless Batch AI
Beforehand, most AI Capabilities both had throughput limits or required devoted endpoint provisioning, which restricted their use at excessive scale or added operational overhead in managing and sustaining endpoints.
Beginning in the present day, AI Capabilities are absolutely serverless—no endpoint setup wanted at any scale! Merely name ai_query or task-based features like ai_classify or ai_translate, and inference runs immediately, irrespective of the desk measurement. The Basis Mannequin API Batch Inference service manages useful resource provisioning routinely behind the scenes, scaling up jobs that want excessive throughput whereas delivering predictable job completion occasions.
For extra management, ai_query() nonetheless helps you to select particular Llama or GTE embedding fashions, with help for added fashions coming quickly. Different fashions, together with fine-tuned LLMs, exterior LLMs (similar to Anthropic & OpenAI), and classical AI fashions, can even nonetheless be used with ai_query() by deploying them on Mosaic AI Mannequin Serving.
2. >10x Sooner Batch Inference
We have now optimized our system for Batch Inference at each layer. Basis Mannequin API now gives a lot larger throughput that allows quicker job completion occasions and industry-leading TCO for Llama mannequin inference. Moreover, long-running batch inference jobs are actually considerably quicker attributable to our programs intelligently allocating capability to jobs. AI features are capable of adaptively scale up backend site visitors, enabling production-grade reliability.
Because of this, AI Capabilities execute >10x quicker, and in some circumstances as much as 100x quicker, lowering processing time from hours to minutes. These optimizations apply throughout general-purpose (ai_query) and task-specific (ai_classify, ai_translate) features, making Batch AI sensible for high-scale workloads.
| Workload | Earlier Runtime (s) | New Runtime (s) | Enchancment |
|---|---|---|---|
| Summarize 10,000 paperwork | 20,400 | 158 | 129x quicker |
| Classify 10,000 buyer help interactions | 13,740 | 73 | 188x quicker |
| Translate 50,000 texts | 543,000 | 658 | 852x quicker |
3. Simply extract structured insights with Structured Output
GenAI fashions have proven superb promise at serving to analyze massive corpuses of unstructured information. We’ve discovered quite a few companies profit from with the ability to specify a schema for the info they need to extract. Nonetheless, beforehand, of us relied on brittle immediate engineering strategies and generally repeated queries to iterate on the reply to reach at a closing reply with the proper construction.
To resolve this downside, AI Capabilities now help Structured Output, permitting you to outline schemas instantly in queries and utilizing inference-layer strategies to make sure mannequin outputs conform to the schema. We have now seen this characteristic dramatically enhance efficiency for structured technology duties, enabling companies to launch it into manufacturing shopper apps. With a constant schema, customers can guarantee consistency of responses and simplify integration into downstream workflows.
Instance: Extract structured metadata from analysis papers:
4. Actual-Time Observability & Reliability
Monitoring the progress of your batch inference job is now a lot simpler. We floor dwell statistics about inference failures to assist monitor down any efficiency issues or invalid information. All this information might be discovered within the Question Profile UI, which gives real-time execution standing, processing occasions, and error visibility. In AI Capabilities, we’ve constructed automated retries that deal with transient failures, and setting the fail_on_error flag to false can guarantee a single unhealthy row doesn’t fail your complete job.
5. Constructed for the Information Intelligence Platform
AI Capabilities run natively throughout the Databricks Intelligence Platform, together with SQL, Notebooks, DBSQL, AI/BI Dashboards, and AI/BI Genie—bringing intelligence to each person, all over the place.
With Spark Structured Streaming and Delta Dwell Tables (coming quickly), you’ll be able to combine AI features with customized preprocessing, post-processing logic, and different AI Capabilities to construct end-to-end AI batch pipelines.
Begin Utilizing Batch Inference with AI Capabilities Now
Batch AI is now less complicated, quicker, and absolutely built-in. Attempt it in the present day and unlock enterprise-scale batch inference with AI.
- Discover the docs to see how AI Capabilities simplify batch inference inside Databricks
- Watch the demo for a step-by-step information to operating batch LLM inference at scale.
- Learn the way to deploy a production-grade Batch AI pipeline at scale.
- Take a look at the Compact Information to AI Brokers to learn to maximize your GenAI ROI.










{kind=link}